lunes, 21 de febrero de 2011
Normalización de bases de datos
El modelo entidad relación se basa como un sitio web en red aprobado por la IEEE. Originalmente era un concepto para estudiantes de la Universidad Harvard, pero actualmente está abierto a cualquier persona que tenga un proyecto de base de datos abierto (SQL, MySQL, Oracle).
Se rige por las 3 Formas Normales.
Primera forma normal:
Debe ser una base de datos real, que represente un objeto del mundo y contener tablas basadas en el modelo entidad-relación.
Segunda forma normal:
Debe cumplir la primera forma normal y además hacer referencia con una llave foránea.
Tercera forma normal:
Debe cumplir la segunda forma normal y además contener una clave primaria.
Dependencia funcional Aumentativa
entonces
DNI nombre
DNI,dirección nombre,dirección
Si con el DNI se determina el nombre de una persona, entonces con el DNI más la dirección también se determina el nombre o su dirección.

Se rige por las 3 Formas Normales.
Primera forma normal:
Debe ser una base de datos real, que represente un objeto del mundo y contener tablas basadas en el modelo entidad-relación.
Segunda forma normal:
Debe cumplir la primera forma normal y además hacer referencia con una llave foránea.
Tercera forma normal:
Debe cumplir la segunda forma normal y además contener una clave primaria.
Dependencia funcional Aumentativa
entonces
DNI nombre
DNI,dirección nombre,dirección
Si con el DNI se determina el nombre de una persona, entonces con el DNI más la dirección también se determina el nombre o su dirección.
Dependencia funcional transitiva

Sean X, Y, Z tres atributos (o grupos de atributos) de la misma entidad. Si Y depende funcionalmente de X y Z de Y, pero X no depende funcionalmente de Y, se dice entonces que Z depende transitivamente de X. Simbólicamente sería:
X 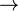 Y Z entonces X Z
Y Z entonces X Z
Y Z entonces X ZFechaDeNacimiento Edad
EdadEdad Conducir
ConducirFechaDeNacimiento Edad Conducir
Edad ConducirEntonces tenemos que FechaDeNacimiento determina a Edad y la Edad determina a Conducir, indirectamente podemos saber a través deFechaDeNacimiento a Conducir (En muchos países, una persona necesita ser mayor de cierta edad para poder conducir un automóvil, por eso se utiliza este ejemplo).
Formas Normales
Las formas normales son aplicadas a las tablas de una base de datos. Decir que una base de datos está en la forma normal N es decir que todas sus tablas están en la forma normal N.
Communications of the ACM, Vol. 13, No. 6, June 1970, pp. 377-387 [1]</ref>
Primera Forma Normal (1FN)
Todos los atributos son atómicos. Un atributo es atómico si los elementos del dominio son indivisibles, mínimos.
La tabla contiene una clave primaria.
La clave primaria no contiene atributos nulos.
No debe existir variación en el número de columnas.
Los Campos no clave deben identificarse por la clave (Dependencia Funcional)
Una tupla no puede tener múltiples valores en cada columna. Los datos son atómicos. (Si a cada valor de X le pertenece un valor de Y y viceversa)
Esta forma normal elimina los valores repetidos dentro de una BD
Segunda Forma Normal (2FN)
Dependencia Funcional. Una relación está en 2FN si está en 1FN y si los atributos que no forman parte de ninguna clave dependen de forma completa de la clave principal. Es decir que no existen dependencias parciales. (Todos los atributos que no son clave principal deben depender únicamente de la clave principal).
En otras palabras podríamos decir que la segunda forma normal está basada en el concepto de dependencia completamente funcional. Una dependencia funcional es completamente funcional si al eliminar los atributos A de X significa que la dependencia no es mantenida, esto es que . Una dependencia funcional es una dependencia parcial si hay algunos atributos que pueden ser eliminados de X y la dependencia todavía se mantiene, esto es .
Por ejemplo {DNI, ID_PROYECTO} HORAS_TRABAJO (con el DNI de un empleado y el ID de un proyecto sabemos cuántas horas de trabajo por semana trabaja un empleado en dicho proyecto) es completamente dependiente dado que ni DNI HORAS_TRABAJO ni ID_PROYECTO HORAS_TRABAJO mantienen la dependencia. Sin embargo {DNI, ID_PROYECTO} NOMBRE_EMPLEADO es parcialmente dependiente dado que DNI NOMBRE_EMPLEADO mantiene la dependencia.
Tercera Forma Normal (3FN)
La tabla se encuentra en 3FN si es 2FN y si no existe ninguna dependencia funcional transitiva entre los atributos que no son clave.
Un ejemplo de este concepto sería que, una dependencia funcional X->Y en un esquema de relación R es una dependencia transitiva si hay un conjunto de atributos Z que no es un subconjunto de alguna clave de R, donde se mantiene X->Z y Z->Y.
Por ejemplo, la dependencia SSN->DMGRSSN es una dependencia transitiva en EMP_DEPT de la siguiente figura. Decimos que la dependencia de DMGRSSN el atributo clave SSN es transitiva vía DNUMBER porque las dependencias SSN→DNUMBER y DNUMBER→DMGRSSN son mantenidas, y DNUMBER no es un subconjunto de la clave de EMP_DEPT. Intuitivamente, podemos ver que la dependencia de DMGRSSN sobre DNUMBER es indeseable en EMP_DEPT dado que DNUMBER no es una clave de EMP_DEPT.
Formalmente, un esquema de relacion R está en 3 Forma Normal Elmasri-Navathe,1 si para toda dependencia funcional , se cumple al menos una de las siguientes condiciones:
1. X es superllave o clave.
2. A es atributo primo de R; esto es, si es miembro de alguna clave en R.
Además el esquema debe cumplir necesariamente, con las condiciones de segunda forma normal.
Forma normal de Boyce-Codd (FNBC)
La tabla se encuentra en FNBC si cada determinante, atributo que determina completamente a otro, es clave candidata. Deberá registrarse de forma anillada ante la presencia de un intervalo seguido de una formalizacion perpetua, es decir las variantes creadas, en una tabla no se llegaran a mostrar, si las ya planificadas, dejan de existir.
Formalmente, un esquema de relación R está en FNBC, si y sólo si, para toda dependencia funcional válida en R, se cumple que
1. X es superllave o clave.
De esta forma, todo esquema R que cumple FNBC, está además en 3FN; sin embargo, no todo esquema R que cumple con 3FN, está en FNBC.
Cuarta Forma Normal (4FN)
Una tabla se encuentra en 4FN si, y sólo si, para cada una de sus dependencias múltiples no funcionales X->->Y, siendo X una super-clave que, X es o una clave candidata o un conjunto de claves primarias.
Diagrama de inclusión de todas las formas normales.
Quinta Forma Normal (5FN)
Una tabla se encuentra en 5FN si:
La tabla está en 4FN
No existen relaciones de dependencias no triviales que no siguen los criterios de las claves. Una tabla que se encuentra en la 4FN se dice que está en la 5FN si, y sólo si, cada relación de dependencia se encuentra definida por las claves candidatas.
Reglas de Codd
Codd se percató de que existían bases de datos en el mercado las cuales decían ser relacionales, pero lo único que hacían era guardar la información en las tablas, sin estar estas tablas literalmente normalizadas; entonces éste publicó 12 reglas que un verdadero sistema relacional debería tener, en la práctica algunas de ellas son difíciles de realizar. Un sistema podrá considerarse "más relacional" cuanto más siga estas reglas.
Regla No. 1 - La Regla de la información
Toda la información en un RDBMS está explícitamente representada de una sola manera por valores en una tabla.
Cualquier cosa que no exista en una tabla no existe del todo. Toda la información, incluyendo nombres de tablas, nombres de vistas, nombres de columnas, y los datos de las columnas deben estar almacenados en tablas dentro de las bases de datos. Las tablas que contienen tal información constituyen el Diccionario de Datos. Esto significa que todo tiene que estar almacenado en las tablas.
Toda la información en una base de datos relacional se representa explícitamente en el nivel lógico exactamente de una manera: con valores en tablas. Por tanto los metadatos (diccionario, catálogo) se representan exactamente igual que los datos de usuario. Y puede usarse el mismo lenguaje (ej. SQL) para acceder a los datos y a los metadatos (regla 4)
Regla No. 2 - La regla del acceso garantizado
Cada ítem de datos debe ser lógicamente accesible al ejecutar una búsqueda que combine el nombre de la tabla, su clave primaria, y el nombre de la columna.
Esto significa que dado un nombre de tabla, dado el valor de la clave primaria, y dado el nombre de la columna requerida, deberá encontrarse uno y solamente un valor. Por esta razón la definición de claves primarias para todas las tablas es prácticamente obligatoria.
Regla No. 3 - Tratamiento sistemático de los valores nulos
La información inaplicable o faltante puede ser representada a través de valores nulos
Un RDBMS (Sistema Gestor de Bases de Datos Relacionales) debe ser capaz de soportar el uso de valores nulos en el lugar de columnas cuyos valores sean desconocidos.
Regla No. 4 - La regla de la descripción de la base de datos
La descripción de la base de datos es almacenada de la misma manera que los datos ordinarios, esto es, en tablas y columnas, y debe ser accesible a los usuarios autorizados.
La información de tablas, vistas, permisos de acceso de usuarios autorizados, etc, debe ser almacenada exactamente de la misma manera: En tablas. Estas tablas deben ser accesibles igual que todas las tablas, a través de sentencias de SQL (o similar).
[editar]Regla No. 5 - La regla del sub-lenguaje Integral
Debe haber al menos un lenguaje que sea integral para soportar la definición de datos, manipulación de datos, definición de vistas, restricciones de integridad, y control de autorizaciones y transacciones.
Esto significa que debe haber por lo menos un lenguaje con una sintaxis bien definida que pueda ser usado para administrar completamente la base de datos.
Regla No. 6 - La regla de la actualización de vistas
Todas las vistas que son teóricamente actualizables, deben ser actualizables por el sistema mismo.
La mayoría de las RDBMS permiten actualizar vistas simples, pero deshabilitan los intentos de actualizar vistas complejas.
Regla No. 7 - La regla de insertar y actualizar
La capacidad de manejar una base de datos con operandos simples aplica no sólo para la recuperación o consulta de datos, sino también para la inserción, actualización y borrado de datos'.
Esto significa que las cláusulas para leer, escribir, eliminar y agregar registros (SELECT, UPDATE, DELETE e INSERT en SQL) deben estar disponibles y operables, independientemente del tipo de relaciones y restricciones que haya entre las tablas.
[editar]Regla No. 8 - La regla de independencia física
El acceso de usuarios a la base de datos a través de terminales o programas de aplicación, debe permanecer consistente lógicamente cuando quiera que haya cambios en los datos almacenados, o sean cambiados los métodos de acceso a los datos.
El comportamiento de los programas de aplicación y de la actividad de usuarios vía terminales debería ser predecible basados en la definición lógica de la base de datos, y éste comportamiento debería permanecer inalterado, independientemente de los cambios en la definición física de ésta.
Regla No. 9 - La regla de independencia lógica
Los programas de aplicación y las actividades de acceso por terminal deben permanecer lógicamente inalteradas cuando quiera que se hagan cambios (según los permisos asignados) en las tablas de la base de datos.
La independencia lógica de los datos especifica que los programas de aplicación y las actividades de terminal deben ser independientes de la estructura lógica, por lo tanto los cambios en la estructura lógica no deben alterar o modificar estos programas de aplicación.
Regla No. 10 - La regla de la independencia de la integridad
Todas las restricciones de integridad deben ser definibles en los datos, y almacenables en el catalogo, no en el programa de aplicación.
Las reglas de integridad
- Ningún componente de una clave primaria puede tener valores en blanco o nulos (ésta es la norma básica de integridad).
- Para cada valor de clave foránea deberá existir un valor de clave primaria concordante. La combinación de estas reglas aseguran que haya integridad referencial.
Regla No. 11 - La regla de la distribución
El sistema debe poseer un lenguaje de datos que pueda soportar que la base de datos esté distribuida físicamente en distintos lugares sin que esto afecte o altere a los programas de aplicación.
El soporte para bases de datos distribuidas significa que una colección arbitraria de relaciones, bases de datos corriendo en una mezcla de distintas máquinas y distintos sistemas operativos y que esté conectada por una variedad de redes, pueda funcionar como si estuviera disponible como en una única base de datos en una sola máquina.
Regla No. 12 - Regla de la no-subversión
Si el sistema tiene lenguajes de bajo nivel, estos lenguajes de ninguna manera pueden ser usados para violar la integridad de las reglas y restricciones expresadas en un lenguaje de alto nivel (como SQL).
Algunos productos solamente construyen una interfaz relacional para sus bases de datos No relacionales, lo que hace posible la subversión (violación) de las restricciones de integridad. Esto no debe ser permitido.
Referencias
- ↑ Fundamentals of DATABASE SYSTEMS Addison Wesley;, ISBN-10: 0321122267, ISBN-13: 978-0321122261,
- E.F.Codd (junio de 1970). "A Relational Model of Data for Large Shared Databanks". Communications of the ACM.
- C.J.Date (1994). "An Introduction to Database Systems". Addison-Wesley.
viernes, 18 de febrero de 2011
Lenguajes de Programacion compatibles con SQL
xisten varias APIs que permiten, a aplicaciones escritas en diversos lenguajes de programación, acceder a las bases de datos MySQL, incluyendo C, C++, C#, Pascal, Delphi (via dbExpress), Eiffel, Smalltalk, Java (con una implementación nativa del driver de Java), Lisp, Perl,PHP, Python, Ruby,Gambas, REALbasic (Mac y Linux), (x)Harbour (Eagle1), FreeBASIC, y Tcl; cada uno de estos utiliza una APIespecífica. También existe una interfaz ODBC, llamado MyODBC que permite a cualquier lenguaje de programación que soporte ODBCcomunicarse con las bases de datos MySQL. También se puede acceder desde el sistema SAP, lenguaje ABAP.
Referencia: http://es.wikipedia.org/wiki/MySQL#Lenguajes_de_programaci.C3.B3n
Referencia: http://es.wikipedia.org/wiki/MySQL#Lenguajes_de_programaci.C3.B3n
lunes, 7 de febrero de 2011
Base de Datos
CREATE database nombre_bd;
USE nombre_bd
CREATE TABLE usuario(
clave INT NOTNULL primary key,
nombre VARCHAR(20) NOTNULL,
DIRECCION VARCHAR(30) NOTNULL,
TELEFONO VARCHAR(10) NOTNULL,
EMAIL VARCHAR(20) NOTNULL,
OCUPACION VARCHAR(20) NOTNULL,
)EGINE = INNOBD;
CREATE TABLE LIBRO(
ISBN VARCHAR(20) NOTNULL PRIMARY KEY,
TITULO VARCHAR(20) NOTNULL,
AUTOR VARCHAR (30) NOTNULL,
NEDICION VARCHAR(20) NOTNULL,
NEJEMPLAR VARCHAR (20) NOTNULL,
)ENGINE = INNOBD;
CREATE TABLE EJEMPLAR(
ISBN VARCHAR(20) NOTNULL,
NUMEJEMPLAR VARCHAR(20) NOTNULL,
EDOCONSERVACION VARCHAR(2'0) NOTNULL
PRIMARY KEY(ISBN,NUMEJEMPLAR),
FOREINGN KEY (ISBN) REFERENCES LIBRO(ISBN)
)ENGINE = INNODB;
CREATE TABLE PRESTAMO(
CLAVEUSUARIO VARCHAR(20) NOTNULL PRIMARY KEY,
ISBN VARCHAR(20) NOTNULL,
NUMEJEMPLAR VARCHAR(10) NOTNULL,
MULTA INT NOTNULL,
FOREINGN KEY (ISBN) REFERENCES EJEMPLAR(ISBN),
FOREINGN KEY (NUMEJEMPLAR) REFERENCES EJEMPLAR(NUMEJEMPLAR),
)ENGINE = INNODB;
USE nombre_bd
CREATE TABLE usuario(
clave INT NOTNULL primary key,
nombre VARCHAR(20) NOTNULL,
DIRECCION VARCHAR(30) NOTNULL,
TELEFONO VARCHAR(10) NOTNULL,
EMAIL VARCHAR(20) NOTNULL,
OCUPACION VARCHAR(20) NOTNULL,
)EGINE = INNOBD;
CREATE TABLE LIBRO(
ISBN VARCHAR(20) NOTNULL PRIMARY KEY,
TITULO VARCHAR(20) NOTNULL,
AUTOR VARCHAR (30) NOTNULL,
NEDICION VARCHAR(20) NOTNULL,
NEJEMPLAR VARCHAR (20) NOTNULL,
)ENGINE = INNOBD;
CREATE TABLE EJEMPLAR(
ISBN VARCHAR(20) NOTNULL,
NUMEJEMPLAR VARCHAR(20) NOTNULL,
EDOCONSERVACION VARCHAR(2'0) NOTNULL
PRIMARY KEY(ISBN,NUMEJEMPLAR),
FOREINGN KEY (ISBN) REFERENCES LIBRO(ISBN)
)ENGINE = INNODB;
CREATE TABLE PRESTAMO(
CLAVEUSUARIO VARCHAR(20) NOTNULL PRIMARY KEY,
ISBN VARCHAR(20) NOTNULL,
NUMEJEMPLAR VARCHAR(10) NOTNULL,
MULTA INT NOTNULL,
FOREINGN KEY (ISBN) REFERENCES EJEMPLAR(ISBN),
FOREINGN KEY (NUMEJEMPLAR) REFERENCES EJEMPLAR(NUMEJEMPLAR),
)ENGINE = INNODB;
Sistemas Gestores de Bases de Datos
Los sistemas de gestión de bases de datos (en inglés database management system, abreviado DBMS) son un tipo de software muy específico, dedicado a servir de interfaz entre la base de datos, el usuario y las aplicaciones que la utilizan.
El propósito general de los sistemas de gestión de bases de datos es el de manejar de manera clara, sencilla y ordenada un conjunto de datos que posteriormente se convertirán en información relevante para una organización.
Existen distintos objetivos que deben cumplir los SGBD:
Abstracción de la información. Los SGBD ahorran a los usuarios detalles acerca del almacenamiento físico de los datos. Da lo mismo si una base de datos ocupa uno o cientos de archivos, este hecho se hace transparente al usuario. Así, se definen varios niveles de abstracción.
Independencia. La independencia de los datos consiste en la capacidad de modificar el esquema (físico o lógico) de una base de datos sin tener que realizar cambios en las aplicaciones que se sirven de ella.
Consistencia. En aquellos casos en los que no se ha logrado eliminar la redundancia, será necesario vigilar que aquella información que aparece repetida se actualice de forma coherente, es decir, que todos los datos repetidos se actualicen de forma simultánea. Por otra parte, la base de datos representa una realidad determinada que tiene determinadas condiciones, por ejemplo que los menores de edad no pueden tener licencia de conducir. El sistema no debería aceptar datos de un conductor menor de edad. En los SGBD existen herramientas que facilitan la programación de este tipo de condiciones.
Seguridad. La información almacenada en una base de datos puede llegar a tener un gran valor. Los SGBD deben garantizar que esta información se encuentra segura de permisos a usuarios y grupos de usuarios, que permiten otorgar diversas categorías de permisos.
Manejo de transacciones. Una transacción es un programa que se ejecuta como una sola operación. Esto quiere decir que luego de una ejecución en la que se produce una falla es el mismo que se obtendría si el programa no se hubiera ejecutado. Los SGBD proveen mecanismos para programar las modificaciones de los datos de una forma mucho más simple que si no se dispusiera de ellos.
Tiempo de respuesta. Lógicamente, es deseable minimizar el tiempo que el SGBD demora en proporcionar la información solicitada y en almacenar los cambios realizados.
Típicamente, es necesario disponer de una o más personas que administren la base de datos, de la misma forma en que suele ser necesario en instalaciones de cierto porte disponer de una o más personas que administren los sistemas operativos. Esto puede llegar a incrementar los costos de operación en una empresa. Sin embargo hay que balancear este aspecto con la calidad y confiabilidad del sistema que se obtiene.
Si se tienen muy pocos datos que son usados por un único usuario por vez y no hay que realizar consultas complejas sobre los datos, entonces es posible que sea mejor usar una planilla de cálculo.
Complejidad: los software muy complejos y las personas que vayan a usarlo deben tener conocimiento de las funcionalidades del mismo para poder aprovecharlo al máximo.
Tamaño: la complejidad y la gran cantidad de funciones que tienen hacen que sea un software de gran tamaño, que requiere de gran cantidad de memoria para poder correr.
Coste del hardware adicional: los requisitos de hardware para correr un SGBD por lo general son relativamente altos, por lo que estos equipos pueden llegar a costar gran cantidad de dinero.
SGBD libres
PostgreSQL
Firebird basada en la versión 6 de InterBase, Initial Developer's PUBLIC LICENSE Version 1.0.
SQLite
DB2 Express-C
Apache Derby
SGBD no libres
MySQL: Licencia Dual, depende del uso. No se sabe hasta cuándo permanecerá así, ya que ha sido comprada por Oracle. Sin embargo, existen 2 versiones: una gratuita que sería equivalente a la edición "express" SQL server de Microsoft Windows, y otra más completa de pago.
Advantage Database
dBase
FileMaker
Fox Pro
gsBase
IBM DB2: Universal Database (DB2 UDB)
IBM Informix
Interbase de CodeGear, filial de Borland
MAGIC
Microsoft Access
Microsoft SQL Server
NexusDB
Open Access
Oracle
Paradox
PervasiveSQL
Progress (DBMS)
Sybase ASE
Sybase ASA
Sybase IQ
WindowBase
IBM IMS Base de Datos Jerárquica
CA-IDMS
SGBD no libres y gratuitos
Microsoft SQL Server Compact Edition Basica
Sybase ASE Express Edition para Linux (edición gratuita para Linux)
Oracle Express Edition 10
Suscribirse a:
Entradas (Atom)